The newest hype in AI race is probably DeepSeek R1 - o1 comparable reasoning but with much lower costs. Lots of discussions on how to use this model right now, such as using R1 to plan and 3.5-Sonnet to generate. Those are super cool ideas. The one idea I want to explore in this article is to use R1 fully on device and see how much of a user experience looks like.
First, let’s get the basics running in Terminal
There are plenty of ways to run LLM locally. I choose Ollama for its simplicity to set things up quickly. My Macbook Pro is M1 Max + 32GB memory. It also has a 32-core GPU. Theoretically, I can run the 32B Qwen distilled one but I realize my machine gets so hot after I run it. So 32B model may not be durable for frequent uses. I decide to use the 8B Llama distilled model instead to keep the machine cool.
Run below command can get you a Terminal window to interact with DeepSeek.
ollama run deepseek-r1:8b
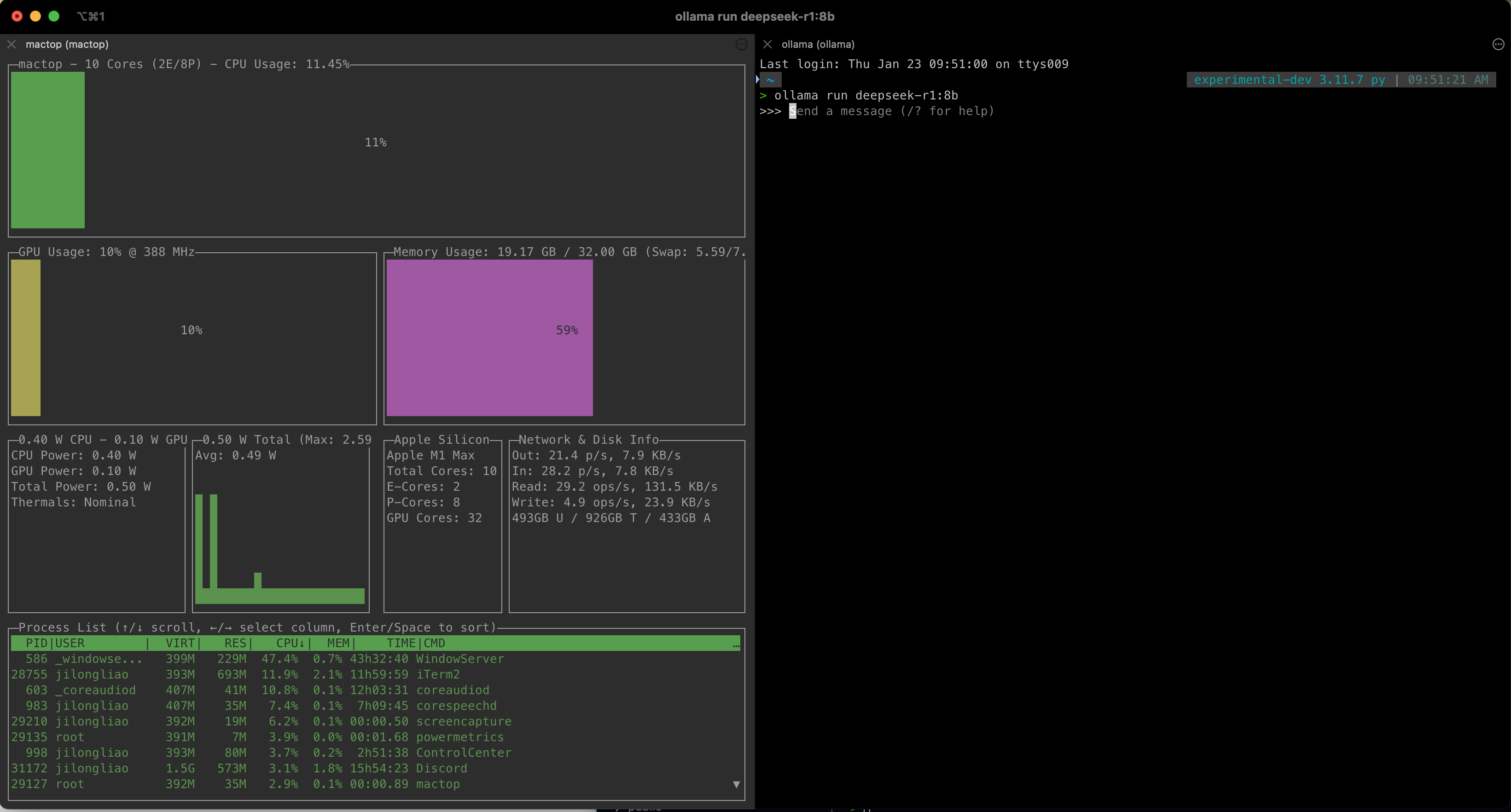
Ollama makes it really easy to get started. I barely need to do anything special but just wait for the program to run.
Next, let’s test out some reasonings
First, I tried a high school algebra II equation questions by just copy and paste into the prompt window in my Terminal.
Tom is painting a fence 100 feet long. He starts at the West end of the fence and paints at a rate of 5 feet per hour. After 2 hours, Huck joins Tom and begins painting from the East end of the fence at a rate of 8 feet per hour. After 2 hours of the two boys painting at the same time, Tom leaves Huck to finish the job by himself.
If Huck completes painting the entire fence after Tom leaves, how many more hours will Huck work than Tom?
There is a clear <think></think> block that tells exact steps to deduct the solution. Pretty clear!
<think>
First, determine Tom's progress before Huck joins him. Tom paints at a rate of 5 feet per hour
for 2 hours, covering 10 feet.
Next, with both Tom and Huck working together, their combined painting rate is 5 + 8 = 13 feet
per hour. Since they work together for another 2 hours, they paint an additional 26 feet,
bringing the total painted length to 36 feet.
After 4 hours in total, Tom leaves Huck to finish the remaining 64 feet of the fence. Huck's
painting rate is 8 feet per hour, so the time he needs to complete the remaining fence is 64
divided by 8, which is 8 hours.
Finally, calculate how many more hours Huck works than Tom. While Tom worked for a total of 4
hours, Huck works for 8 hours, resulting in an additional 4 hours of work.
</think>
Meanwhile, my M1 GPUs are in full load, the token speed is in fact very fast. You can view it from the below screen recording. Honestly, I’m quite enjoy the token speed on my laptop.
Another comparison I did is to compare the token speed between M1 Max and my NVIDIA RTX 3070 (roughly similar time when both product came to market). I can’t tell much difference from just looking at it.
Now, let’s make it user friendly
Using the Terminal is good for quick testing but I would prefer a UI to interact daily. Chatbox AI is a great tool to interact with Ollama server locally. You can use either MacOS app or Web based experience to interact with it. Additionally, code editors like Cline also supports it which could make coding more fun. In this post, I’ll simply use Chatbox AI.
There’s a small setup you’ll need to specify to use Ollama.
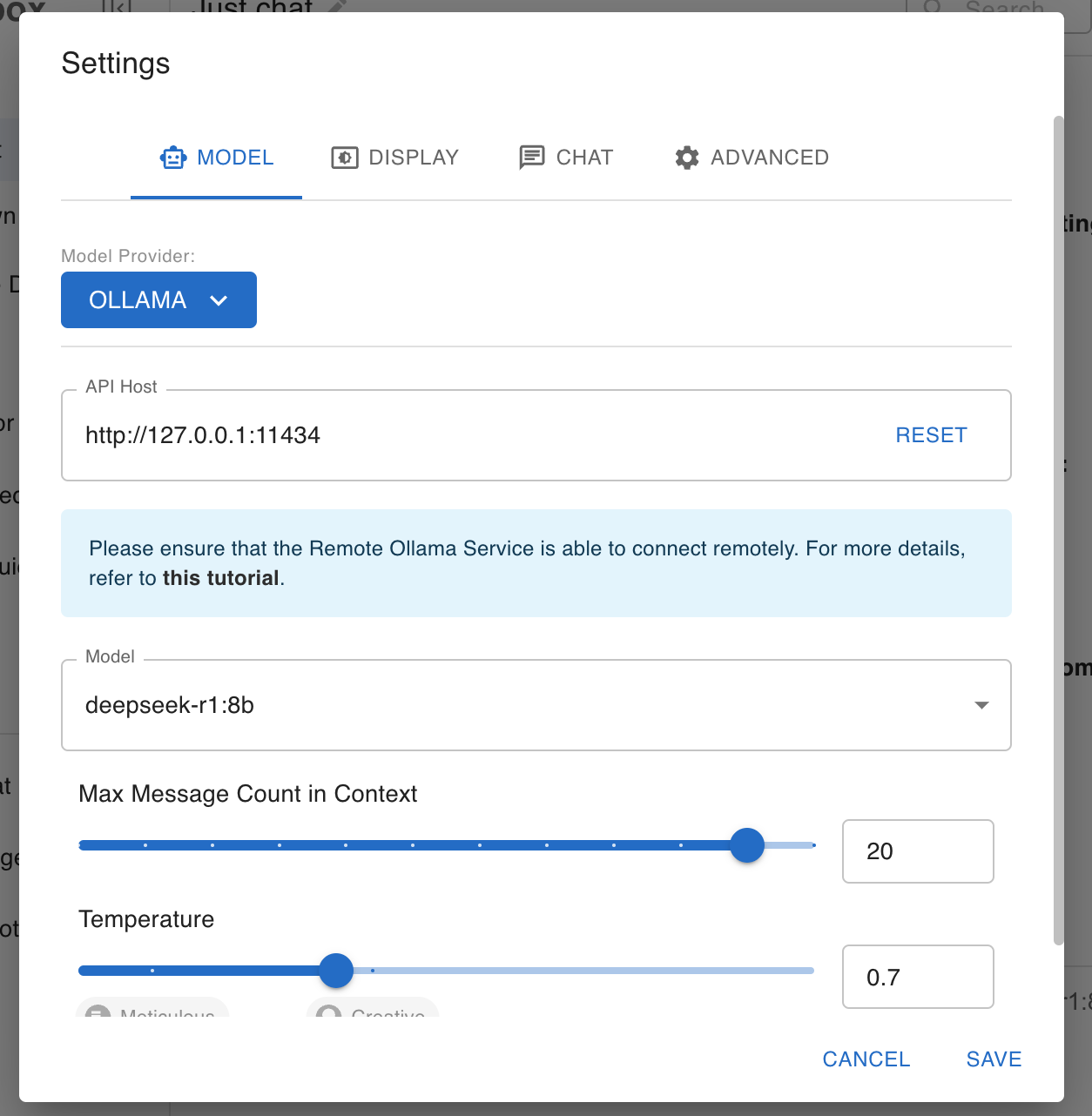
Now, let’s roll it with the same math problem and observe what happens.
Similarly, M1 Max GPU is fully loaded. Latex output is rendered very well. I don’t see any obvious performance differerce.
Overall, I start thinking of a paradigm in Apple Silicon that thinking can be done locally with models like R1, then use Claude 3.5 Sonnet to do the actual generation. This makes AI systems a hybrid mode between edge device and cloud.