One thing I like working at Cruise is the super interesting technical problem space. This article is a recent bug hunting in my team.
At the core of Cruise is the Data Infrastructure systems that provides all the source data collected from the autonomous vehicles. Multiple PBs of data is in and out of this system every single day. Data is stored in a data lake with certain partition and layout, and an n-way data merging service written in Go is reponsible to reconstruct the data into right format the user is requesting.
Gorouting is used in the system that each gorouting opens a file in the object store (like s3://) with some predicate pushed down to specific bytes range of the data. After reading and decompressing, data is streamed and merge sorted. A sorted stream of data is written into a result go channel where the result channel reader flush into a HTTP response stream.
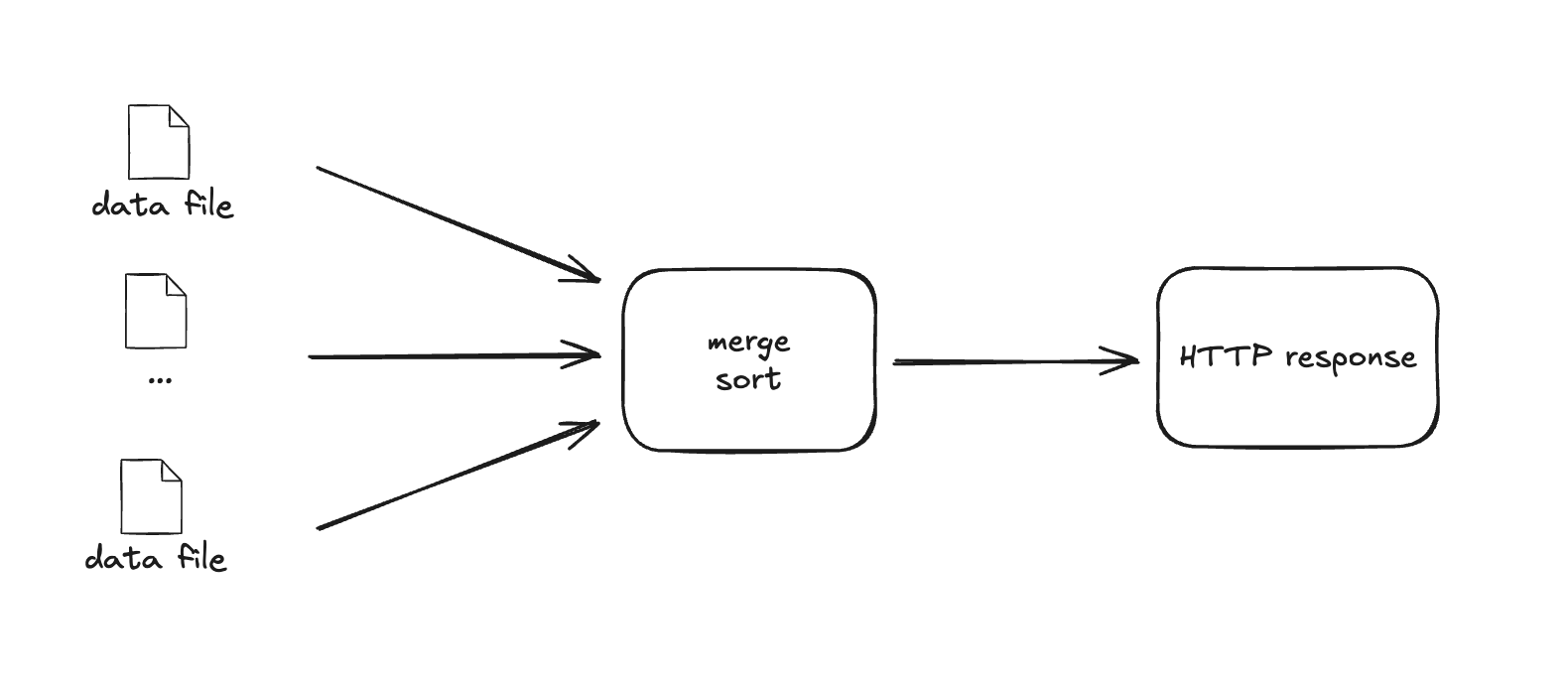
The unbuffered channel is used to synchronize the producers and consumer. The system works fine but the throughput can be improved by 2x by switching to buffered channel. The code change is literally as simple as below.
// result := make(Message)
result := make(Message, 32) // buffer size is 32
The change was rolled out gradually, and everything worked fine except that non deterministic data size was observed occasionally in some rare cases. And we did not understand why but we suspect the buffered channel change introduced some unintended behaviors.
Attempt #1 - can’t reproduce in local
Unfortunately, the issue almost never reproduce in a localhost setup even with the same production setup and problematic data query. But this confirms that some synchronization issue is in the system.
Attempt #2 - rarely reporoduce in local with large replay
About 10k requests in production are sampled and replayed in the local, we identify that vast majority requests are fine, but some rare cases (< 1%) are not. Fortunately, we are able to narrow down to certain types of requests that can have this issue. However, the single run still cannot consistantly reproduce.
Attempt #3 - read the code again and the ah-ha moment!
One thing we notice is that a separate done channel is used to handle some the unhappy path edge cases such as no further data for result and force to exit.
// data producer pseudo code
result := make(Message, 32) // buffered
done := make(bool) // unbuffered
defer func(){
done <- false
}()
pq := make(...) // the priority queue for sorting
for len(pq) > 0 {
item = pq[0]
result <- item // produce data into result channel
... // adding data into pq
}
On the consumer side, the done channel can signal the termination of the process given sorting is complete.
// data consumer pseudo code
select {
case r := <- result:
http.flush(r)
case d := <- done:
http.close()
}
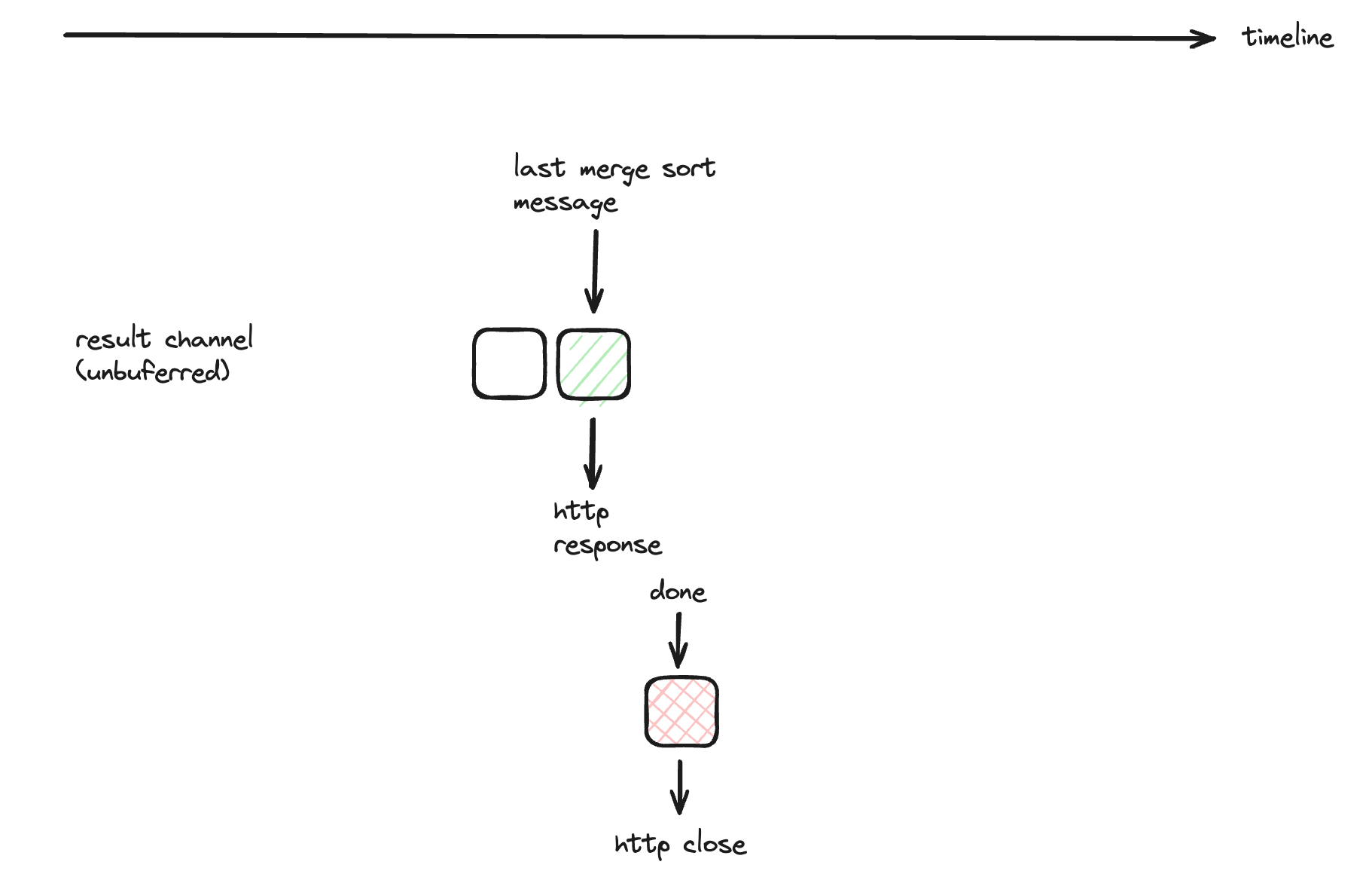
The consumer code works fine when result is unbuffered because the unbuffered channel is synchronized and it’ll wait for the last message being flushed in order to complete the producer’s priority queue loop which sends done signal by the defer function. The following diagram explains it in visual that the done channel is guaranteed to be after the last message of result channel. Hence there was no synchronization issue.
Changing result into buffered channel can make the data producer code runs faster than data consumer code. Especially in surge traffic, the http response flush can runs behind of the data producer. This means len(result) > 0 when receiving done signal.
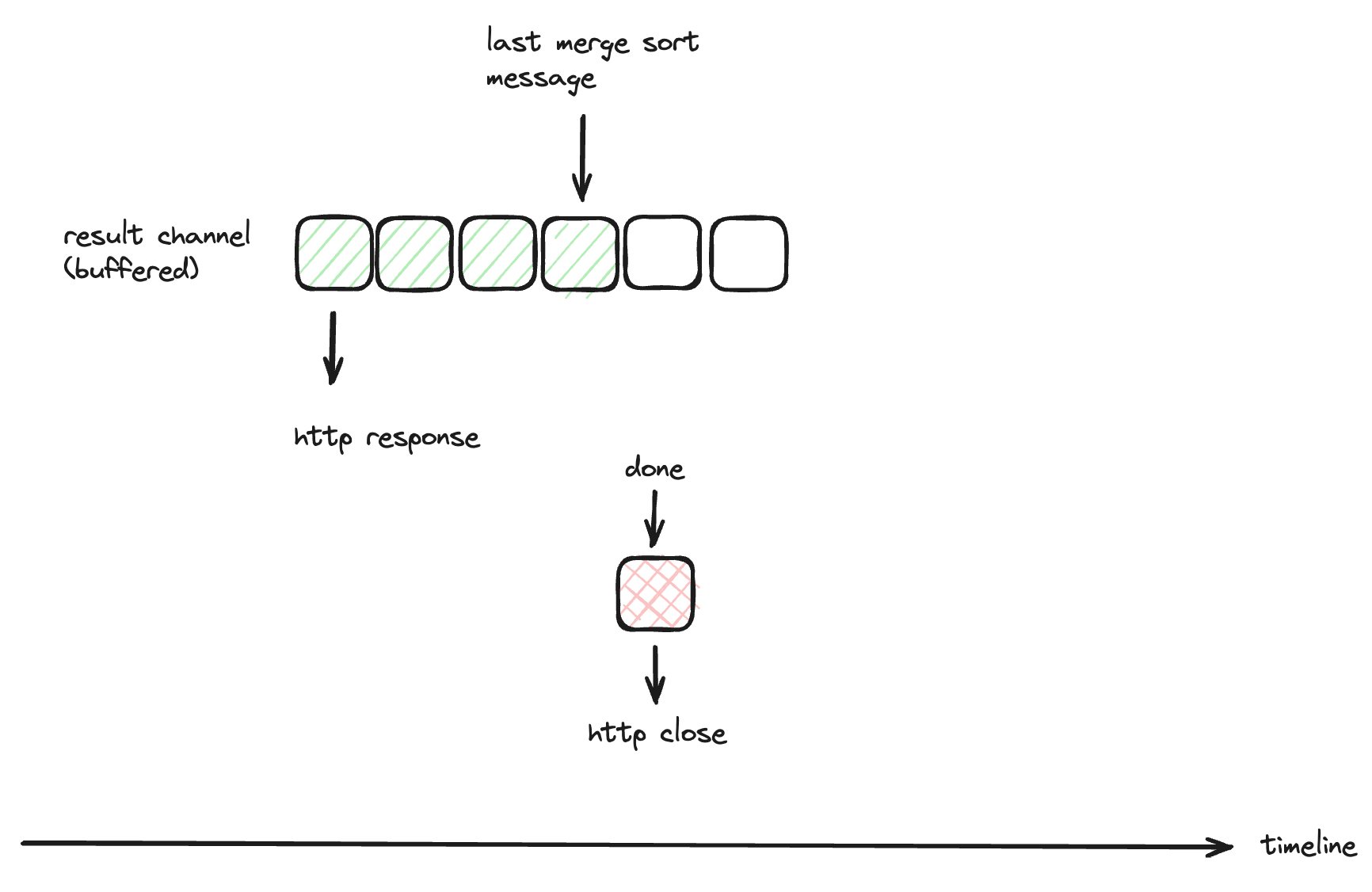
Assume the result channel size is 6 from the above diagram, the http flush is 3 messages behind while the last message has been written into result channel and signal the done channel. At the moment the consumer receives the done channel, the http resonse closes and the remaining 3 messages are discarded.
Attempt #4 - confirm the hypothesis.
A simple intrumentation is added to log the remaining messages in the result channel, and we confirmed it is the case.
// data consumer pseudo code
select {
case r := <- result:
http.flush(r)
case d := <- done:
metric.increase("remaining-result", len(result))
http.close()
}
Attempt #5 - fix it.
The fix is simple to use the same result channel with a special message to signal done instead of a separate done channel.
// data producer pseudo code
result := make(Message, 32) // buffered
defer func(){
eofMessage := Message{} // an empty message
result <- eofMessage
}()
pq := make(...) // the priority queue for sorting
for len(pq) > 0 {
item = pq[0]
result <- item // produce data into result channel
... // adding data into pq
}
// =========================================================
// data consumer pseudo code
select {
case r := <- result:
if (Message{}) == r:
http.close()
http.flush(r)
}
A unit test is also introduced to cover this case by adding artifical delay at data consumer.
Some learnings
- Synchronization bugs are difficult to root cause but there are some principles I learned from this experience:
- it’s an iterative process that you build hypothesis and validate it.
- try to narrow down the search scope and reproduce it locally.
- read the code again and again to understand deeply.
- More pairs of eyes are super helpful. Our team had a few live debugging session to run the hypothesis and think through it. This process also helps the team to reach a deeper understanding of the system (especially the legacy ones).