Augmodo is a spatial AI company focusing on augmenting the retail workforce with intelligent AI hardwares. Our products have been deployed into various stores and retail merchandises. At the core of the business is Augmodo’s AI capabilities - recognizing products, detecting out-of-stock, and checking consumer goods compliance etc. All of those AI capabilities depend on reliable data, training and inference infrastructure to accelerate the product iterations. At the center of the flywheel is Skypilot - a platform that allows Augmodo to plan, manage and orchestrate AI workloads from development to production.
In the early days, ML researchers and engineers were using on-prem machines (such as work laptops) to perform dataset generation and training workloads. As Augmodo accumulates more and more data, on-prem machines start to slow down our progress. We have seen issues like the disk is full, training takes forever to complete etc. We quickly migrate to large cloud VMs to run dataset generations and T4 GPU VMs to perform training workloads. However, this didn’t last long as Augmodo kept scaling to more and more stores. We had seen dataset generation reaching TBs level and training workloads taking multiple days to complete on a single node. The need for horizontal scale is desperate.
Augmodo has its unique situations:
- Burst workload and multi-cloud need: the fast moving nature dictates that our data-gen and training workloads burst. The burst GPU (e.g. A100) requirements are getting harder and harder to secure in the primary cloud vendor. A training workload could wait for hours to get the right amount of GPU nodes ready. This hurts our velocity and increases our spending during the waiting time.
- Heterogeneous hardware: our model inference workloads can happen on various architectures: x86 with both data center grade GPUs like T4, consumer grade GPUs like RTX5060, and aarch64 SoC like NVIDIA Jetson series, and customized NPUs like Hailo-8. Our model optimizations and compilations need certain machine types (sometimes hosted on-prem) to accomplish work.
- Multi-modal data: image and text are the two modals that Augmodo is heavily depending on. The dataset generation loop is the process to prepare the training dataset from a mix of structured and unstructured data. A distributed data processing framework with elastic compute is often needed to accomplish the task.
Essentially, Augmodo needs a platform that is ML engineer and researcher friendly, and can natively work with multi-cloud and ad-hoc on-prem machines. In searching for such an open-source platform, we had some principles to guide us on adoption:
- Avoid rebuilding the wheel: we should not build our own unless we cannot find secondary solutions that can together be an OK platform.
- Simplicity: we want a system that is simple, frictionless and easy to understand. This helps our internal adoption.
- Cloud agonistic: we want a system that abstract away the cloud provider we use so that ML researchers and engineers can treat it like “yet another job submission system”.
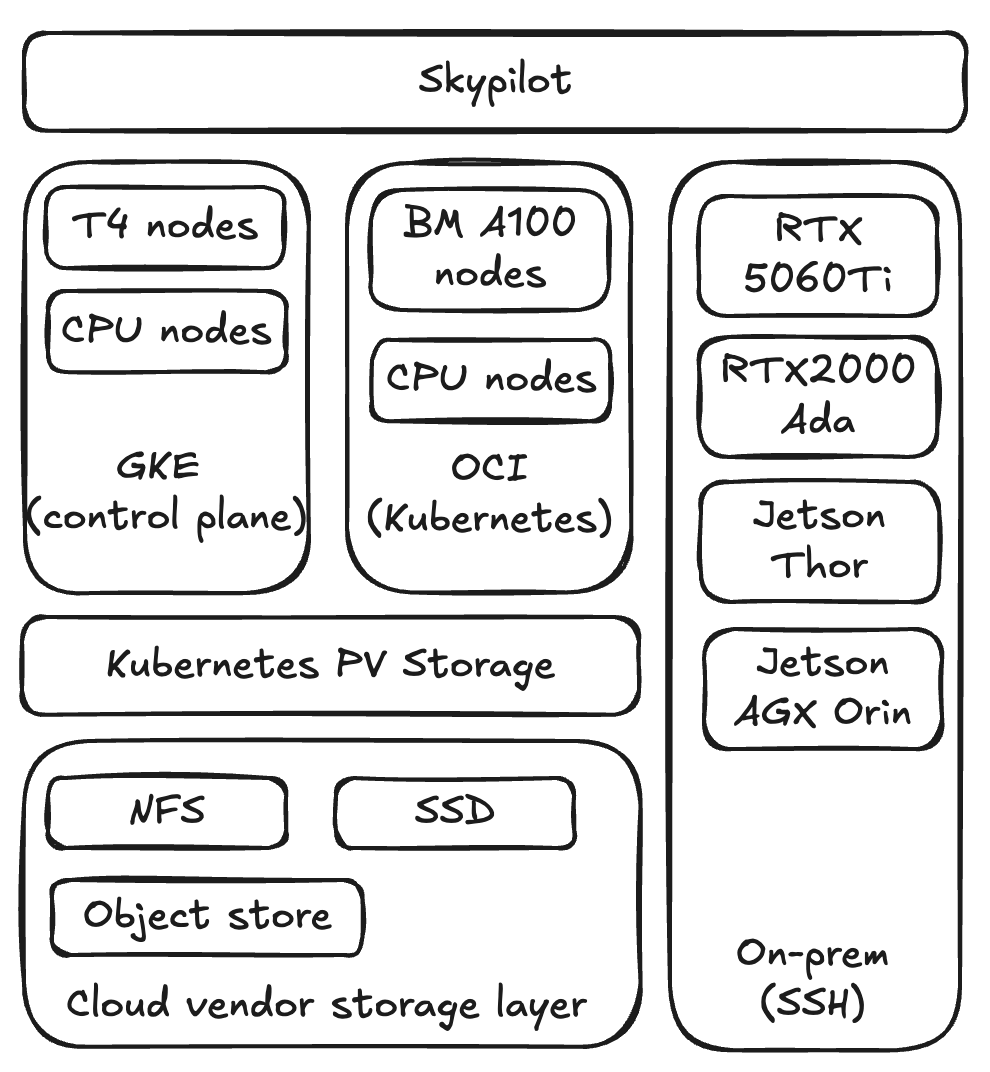
Skypilot is chosen to meet all of our unique situations and principles. Skypilot API server is deployed in a kubernetes cluster in GCP to serve as the control plane. Different types of nodes are also available in GCP, e.g. T4, cpu-only. Users can submit jobs to Skypilot and those jobs can be assigned to in the same cluster as API server.
Augmodo also explores other cloud providers like Oracle for A100 GPU bare-meta nodes. Those compute capabilities are made available as another Kubernetes cluster which is visible in the Skypilot control plane. Users can also specify to run their workloads in OCI BM nodes.
Additionally, for the on-prem dev machines with certain GPU types are built into Skypilot via SSH contexts that a user can access instead of having the user SSH into the machines themselves.
In the cloud setup, users use volume mount of either a Kubernetes PV backed by NFS, SSD etc. or cloud vendor object store directly.
Next, I want to explore the following types of workflow to showcase how we use Skypilot.
Data exploration
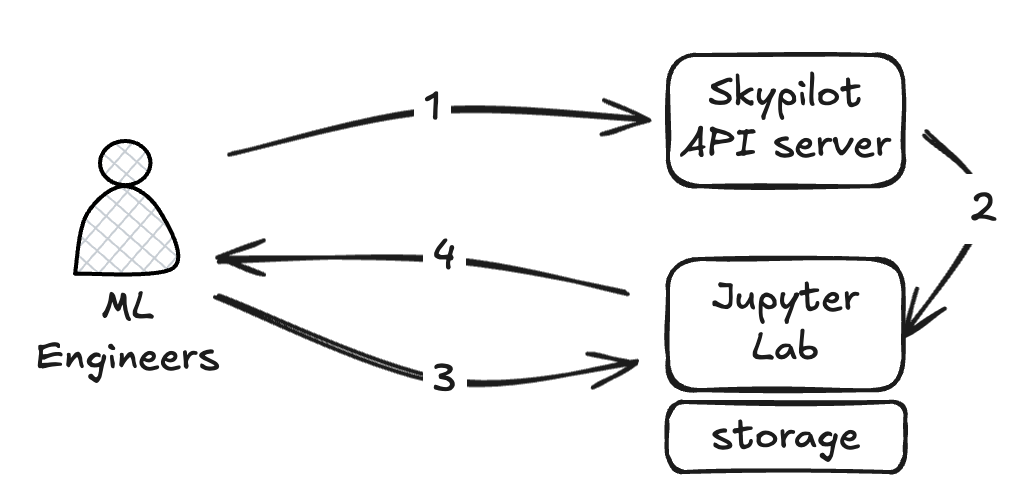
When ML engineers want to explore a dataset, they rely on the jupyter notebook experience from a Skypilot cluster where the storage is mounted and IAM permission properly granted to the Skypilot service account. Typically ML engineers create a jupyter lab cluster via Skypilot API server (step 1 and 2), then directly talk to the jupyter lab cluster (step 3 and 4) from the browser.
Dataset generation
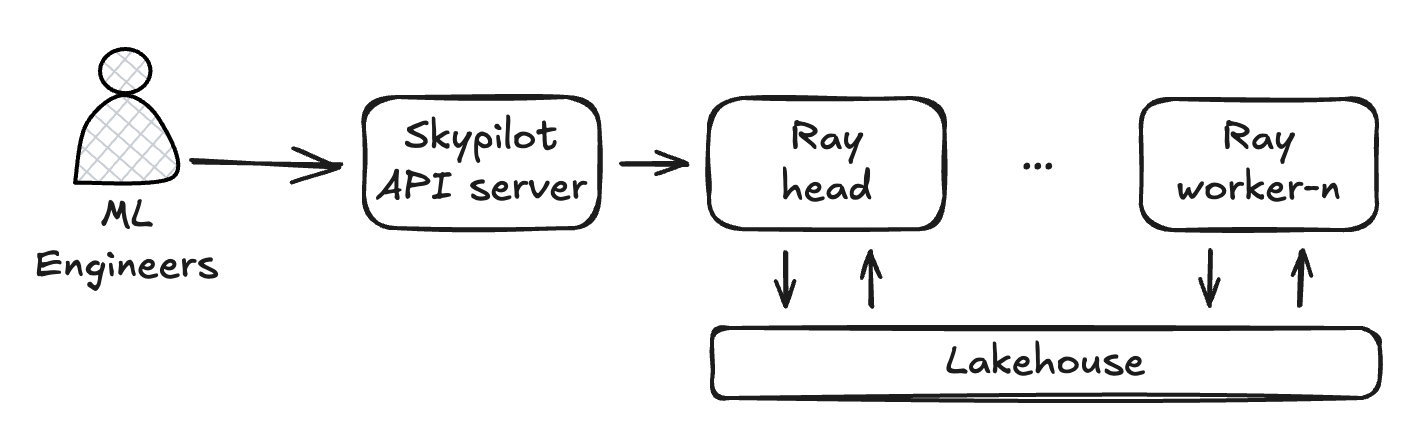
Ray data has been adopted to accelerate the last-mile dataset generation for various training use cases. A ML engineer can launch a pool of Ray workers to work with tables in Lakehouse. Typically a SQL interface is used to find out which data the job needs to pull and transform, then export into a dataset on SSD-backed Kubernetes PV storage for fast data loading in the training loop. The transform and export are highly parallelizable. Skypilot has built-in support for Ray so ML engineers don’t need to worry about issues like networking but just expect Ray to work out of the box like their local machine. Multi-nodes jobs also help to saturate the READ/WRITE bandwidth.
Training loop
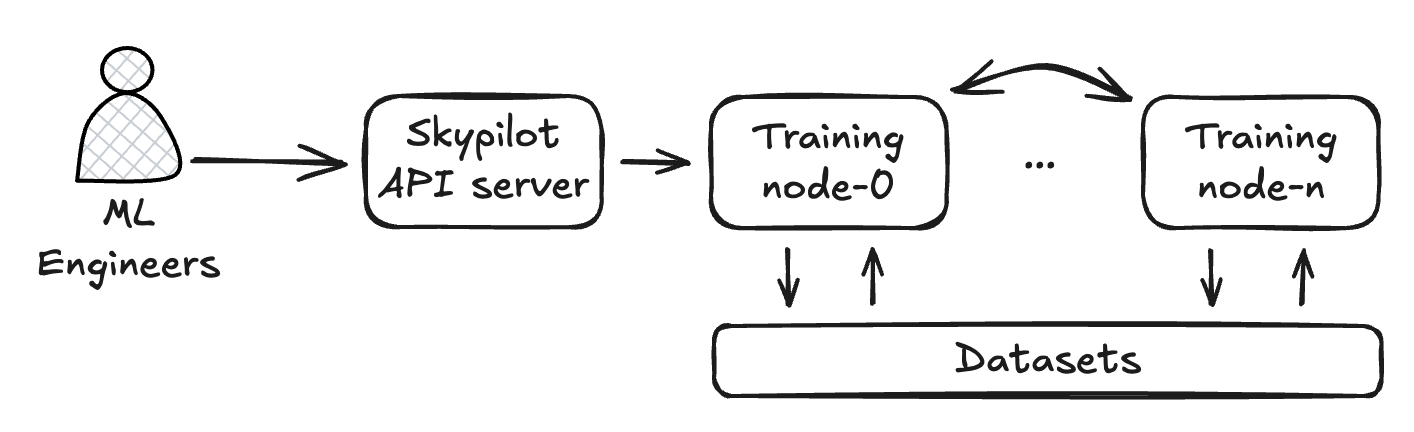
It only took a few weeks from training on a 8x A100 GPU node to multi-node distributed training at Augmodo. The training loop also happens at a high pace. We use Pytorch distributed training for now. Skypilot allows an almost-zero-config experience to launch a cluster of 8x A100 GPU nodes. Those small configurations are easy to understand. We are able to reduce the training from multiple days to less than 12 hours by simply applying the Pytorch distributed setup in Skypilot. This acceleration really speeds up our feature iterations in an extremely low friction way.
Model optimization/compilation loop
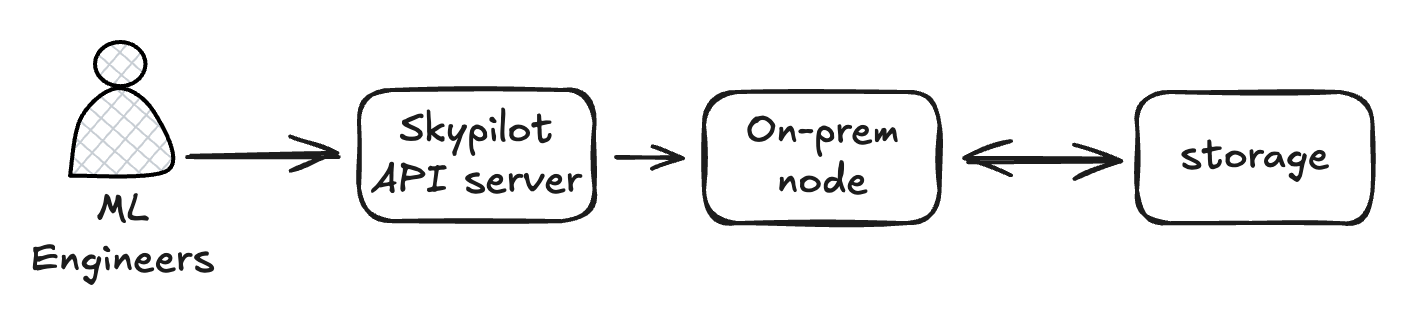
Lastly, once a model is trained, we often optimize and compile the models in TensorRT to leverage the further inference acceleration from NVIDIA. We use Ansible to manage those dev machines that match our production devices, and developers often need to SSH into those machines and treate it like a dev VM. Skypilot actually abstracts away the complexity of managing those dev machines for model optimization and makes it like to just submit a job.
Lessons learned from operations
No system is perfect in operations. We do see operational issues but Skypilot is ahead of us to identify the right solutions. I found some of those issues might be interests to you:
1. Controller High Availability
Originally, we deployed the managed job controller in Kubernetes as a pod. We had a rare physical node shutdown event in GCP that served the controller which caused the controller to disappear and we lost the history. Gladly, the controller has the HA setup which brings high availability to our use cases.
2. Large log volume for managed jobs
Augmodo has very fast paced execution, we submitted thousands of managed jobs within a few weeks of adopting Skypilot. Job logs were stored in the Kubernetes volume which quickly filled up the space. Then the API server became not usable again. Luckily with v0.10.5, we are able to send logs to Google log explorer and have proper log rotations to keep the system lean.
3. API server dashboard slowness
Given the heavy usage of Skypilot, the UI dashboard gets slower to load, which impacts user experience a lot. The v0.10.5 upgrade had significant improvements on API server performance that revitalized the fast dashboard.
4. Increase the likelihood to secure GPUs for burst workloads
Augmodo’s Skypilot is deployed in GKE and 8x A100 GPU nodes are hard to secure for burst workloads. GCP has the dynamic workload scheduler to ease the pressure so that a training job can secure the GPU faster. Essentially, we created the GKE nodepool of 8x A100 GPU with dynamic workload scheduler to help the situation.
5. Node discovery in a different kubernetes cluster than API server cluster
Recently, we expanded to multi-cloud to find better GPU deals. We chose OCI. One issue we found in the Kubernetes setup is that Skypilot API uses the GKE labels to identify GPU nodes while OCI has a different label for those nodes. This fails the pod scheduler. A simple solution here is to apply the GKE label (cloud.google.com/gke-accelerator: nvidia-tesla-a100) to the OCI nodes so that the A100 GPU nodes can be discovered.
Conclusion
SkyPilot has become a cornerstone of our machine learning infrastructure at Augmodo. The platform’s rapid development and feature updates have consistently addressed our scaling needs. By leveraging SkyPilot, we’ve achieved a more resilient and cost-effective GPU orchestration layer that allows our modeling team to focus on building the next generation of spatial AI rather than managing infrastructure.